SQL brut VS constructeur de requête VS mappage d'objet-relationnel en Node.js avec JavaScript
Dans ce billet de blog, nous allons comparer trois grandes différentes manières d'interroger une base de données relationnelle avec le langage de programmation JavaScript depuis Node.js souvent croisés sous les termes de “Raw SQL”, “Query Builder” et “ORM”.
Les bases de données sont au cœur du stockage de l'état de presque toutes les applications web. C'est pourquoi il est essentiel de bien prendre en charge les interactions avec la base de données pour garantir le bon fonctionnement d'une application JavaScript. Une façon d'interagir avec bon nombre de bases de données relationnelles est d'utiliser le SQL (“Structured Query Language”). Le SQL permet de changer très facilement de système de base de données ou de client utilisant cette base de données. Avec votre client, vous pouvez ensuite effectuer les interactions CRUD typiques : C (“Create”) pour Créer, R (“Read”) pour lire, U (“Update”) pour mettre à jour et D (“Delete”) pour supprimer des données.
Après avoir lu cet article, vous en saurez plus sur les différences entre du SQL brut (“Raw SQL”), un constructeur de requêtes (“Query Builder”) et un mappage d'objet-relationnel (“ORM”). Vous saurez également comment utiliser chacun d'entre eux en JavaScript par l'exemple.
Bien que cela ne soit pas nécessaire à la lecture et la compréhension de cet article, tout le code de ce billet est testable après installation du projet associé qui se trouve dans ce dépôt GitHub. Vous devez juste installer un serveur MySQL et Node.js sur votre environnement local. Nous allons faire la supposition que vous êtes déjà familier avec les bases du SQL et du JavaScript en ce qui concerne la compréhension des exemples. Sinon les conclusions, elles, restent abordables pour les non développeurs également (je suppose, je suis mal placer pour le certifier du coup).
Pour initialiser la base de donnée et les tables que nous allons utiliser dans ce billet, vous pouvez utiliser le script database-users-roles.js avec la commande node database-users-roles.js depuis le projet GitHub.
SQL brut dit Raw SQL
Le SQL brut, parfois appelé aussi SQL natif, est la forme la plus élémentaire et la plus basique d'interaction avec une base de données. Vous dites à la base de données ce qu'elle doit faire dans le langage de la base de données. La plupart des développeurs devrait connaître les bases du SQL. Cela signifie qu'ils savent comment créer des tables et des vues, comment sélectionner et joindre des données, comment mettre à jour et supprimer des données. Pour des choses plus complexes comme les procédures stockées, T-SQL, PL-SQL, une connaissance approfondie des indices et de leurs effets cela peut rester l'apanage de quelques spécialistes. Le SQL est bien plus puissant que ne le pensent de nombreux développeurs.
Afin d'illustrer les problèmes posés par les instructions SQL brutes, prenons l'exemple de la gestion des utilisateurs sur une plateforme. Les utilisateurs enregistrés sur la plateforme peuvent consulter des données sur la plateforme s'ils ont le rôle Lecteur et ajouter/modifier/supprimer leurs informations avec le rôle Éditeur. Enfin, un utilisateur avec le rôle Administrateur peut ajouter/modifier/supprimer les informations de tout le monde.
Notez qu'aucune RGPD n'aura été malmené dans cet exemple fictif.
┌───────────────────────────────────────┐
| users | ┌───────────────────────────────────┐
├──────────┬──────────────┬─────────────┤ | roles |
| id | int │ primary key │ ├──────┬──────────────┬─────────────┤
| role_id | int │ index |<─<─<─<┤ id | int │ primary key │
| email | varchar(255) │ index | | name | varchar(255) │ index |
| password | varchar(255) │ index | └──────┴──────────────┴─────────────┘
└──────────┴──────────────┴─────────────┘
Utilisons une page de connexion prenant en entrée utilisateur l'email ainsi que le mot de passe de l'utilisateur respectivement disponibles dans users.email et users.password :
const mysql = require('mysql2');
const connection = mysql.createConnection({
host: "localhost",
user: "root",
password: "root",
database: "raw_builder_orm"
});
// Données provenant de la requête cliente
const email = 'bruno@example.com';
const password = 'foo';
connection.connect(function (err, handshakeResult) {
if (err) throw err;
// Requête SQL à considérer
connection.query(`
SELECT id FROM users WHERE email = '${email}' AND password = '${password}';
`, function (err, rows) {
if (err) throw err;
// Résultat
console.log(rows);
// `[ { id: 2 } ]`
connection.end();
});
});
Pour exécuter ce code, utiliser la commande node raw-sql.js.
Sur une note positive, ce qui se passe avec le SQL brut est assez clair. Vous n'avez besoin que de connaissances en JavaScript et en SQL ainsi qu'un usage basique du connecteur adapté à votre base de donnée. Il n'est pas nécessaire de connaître la logique complémentaire d'une librairie ou d'un framework tiers. Vous pouvez également copier-coller telle quelle les zones de texte pour les vérifier dans un analyseur de syntaxe SQL.
Toutefois, l'utilisation du SQL brut dans le code présente au moins six aspects problématiques dont il faut être conscient.
Problème 1 : injections SQL
Une injection SQL est une attaque sur les requêtes qui utilisent directement des données du client dans une requête SQL que l'attaquant (le client) peut remplir d'une manière inattendue.
Observons deux utilisateurs que nous avons :
id role_id email password
1 1 admin@example.com unknown
2 2 bruno@example.com foo
Il est par exemple facile pour bruno@example.com de savoir que l'utilisateur admin@example.com existe puisque, par exemple, c'est l'adresse à laquelle il faut écrire en cas de problèmes techniques. bruno@example.com connait bien entendu son mot de passe et n'a qu'un rôle de Éditeur. Il suppose que admin@example.com possède un rôle de Administrateur. Alors si l'application utilise du Raw SQL, une injection SQL est possible pour prendre le contrôle de l'application, voyez plutôt :
/* ... */
// Données provenant de la requête cliente
const email = 'bruno@example.com';
const password = `' OR email='admin@example.com' AND '1'='1`;
connection.connect(function (err, handshakeResult) {
// Requête SQL à considérer
connection.query(`
SELECT id FROM users WHERE email = '${email}' AND password = '${password}';
`, function (err, rows) {
// Résultat
console.log(rows);
// `[ { id: 1 } ]`
/* ... */
Pour exécuter ce code, utiliser la commande node raw-sql-issue-1.js.
Avec une telle approche, l'attaquant pourrait remplir son formulaire de connexion avec pour la valeur de l'email qu'il souhaite mais utiliser le champ mot de passe avec cette valeur : ' OR email='admin@example.com' AND '1'='1. Cela donnerait la requête suivante :
SELECT id
FROM users
WHERE
email = 'bruno@example.com' AND
password = ''
OR
email = 'admin@example.com' AND
'1'='1';
Cela indique à l'application que l'utilisateur s'est connecté en tant qu'administrateur car l'entrée retourné ici n'est pas celle de bruno@example.com mais celle de admin@example.com.
Bien sûr, il reste possible d'échapper les guillemets et de ne pas directement utiliser les données de l'utilisateur.
/* ... */
// Données provenant de la requête cliente
const email = 'admin@example.com';
const password = `' OR email='admin@example.com' AND '1'='1`;
connection.connect(function (err, handshakeResult) {
// Requête SQL à considérer
connection.query(`
SELECT id FROM users WHERE email = ? AND password = ?;
`, [
email,
password
], function (err, rows) {
// Résultat
console.log(rows);
// `[]`
/* ... */
Pour exécuter ce code, utiliser la commande node raw-sql-fix-1.js.
Vous constatez alors que dans ce cas, aucun utilisateur ne correspond. Encore faut t-il penser à échapper son code. Les requêtes SQL brutes nécessites donc de prendre en compte cette problématique à tout instant, laissant facilement des portes ouvertes à l'injection si on n'est pas attentif.
Problème 2 : coquilles dans les commandes SQL
Le premier problème évident de la programmation en SQL par chaînes de caractères à l'intérieur d'un fichier identifié comme étant du JavaScript par un éditeur de code est que les fautes de syntaxe dans le sous-langage SQL ne peuvent pas être détectées par l'éditeur de texte. Aussi dans le bout de code suivant :
/* ... */
// Requête SQL à considérer
connection.query(`
SELECT * FROM users WERE email = ? AND password = ?;
`, [
'bruno@example.com',
'foo'
], function (err, rows) {
if (err) err;
// Résultat
console.log(rows);
// `undefined`
/* ... */
Pour exécuter ce code, utiliser la commande node raw-sql-issue-2.js.
l'éditeur n'a pas de moyen de savoir que WERE a une erreur de syntaxe ou même que les ? font parti du mécanisme de la fonction connection.query et qu'ils ne devraient pas être indiqués comme des erreurs si à tout hasard vous trouviez le moyen d'indiquer comment coloriser le SQL dans cette chaine de caractère. Bien sûr, vous pouvez toujours copier-coller telle quelle les zones de texte dans un analyseur de syntaxe SQL mais là encore, il faudra alimenter les ? avec des valeurs ne posant pas problème.
Bien sûr, ce problème peut être détecté à l'exécution avec une gestion des erreurs :
/* ... */
// Requête SQL à considérer
connection.query(`
SELECT * FROM users WERE email = ? AND password = ?;
`, [
'bruno@example.com',
'foo'
], function (err, rows) {
if (err) throw err;
// Error: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'email = 'bruno@example.com' AND password = 'foo'' at line 1
/* ... */
Pour exécuter ce code, utiliser la commande node raw-sql-fix-2.js.
Problème 3 : absence de support pour l'éditeur
Ce problème est assez bête, mais reste un problème ouvert pour de nombreux langages/éditeurs : lorsque les développeurs écrivent leurs requêtes SQL dans une chaîne de caractères en JavaScript, comment l'éditeur peut-il savoir que cette chaîne doit être analysée ? Comment l'éditeur doit-il savoir qu'il veut la coloration syntaxique et/ou l'autocomplétion ?
Par exemple le code suivant provenant d'un fichier avec une extension .js (raw-sql-issue-3.js) :
/* ... */
const select = `
SELECT
u.email,
r.name
`;
const from = `
FROM users AS u
INNER JOIN roles AS r
ON u.role_id = r.id
`;
const where = `
WHERE (
u.email = 'bruno@example.com'
OR
r.name = 'Lecteur'
);
`;
// Requête SQL à considérer
connection.query(select + from + where, function (err, rows) {
// Résultat
console.log(rows);
/*
`[
{ email: 'bruno@example.com', name: 'Éditeur' },
{ email: 'nyx@example.com', name: 'Lecteur' },
{ email: 'noctalie@example.com', name: 'Lecteur' },
{ email: 'dayski@example.com', name: 'Lecteur' }
]`
*/
/* ... */
Pour exécuter ce code, utiliser la commande node raw-sql-issue-3.js.
apparaitra dans Sublime Text 3 comme suit :
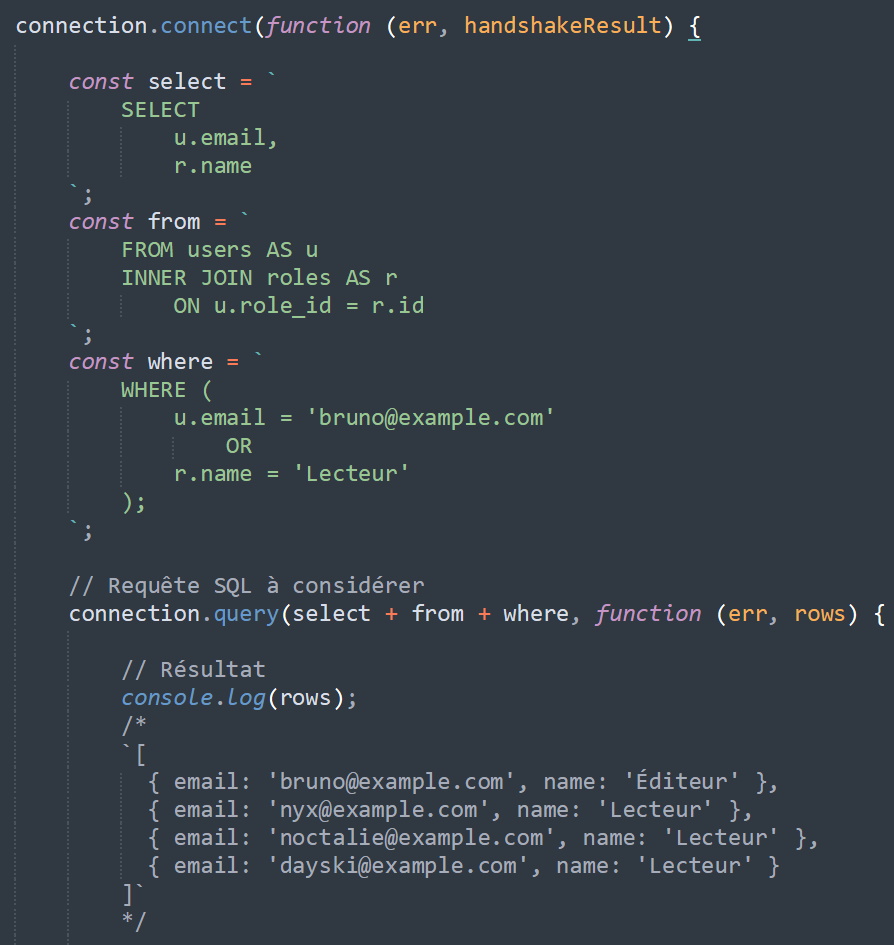
alors que la même portion SQL dans un fichier .sql (raw-sql-fix-3.sql) apparaitra dans Sublime Text 3 comme suit :
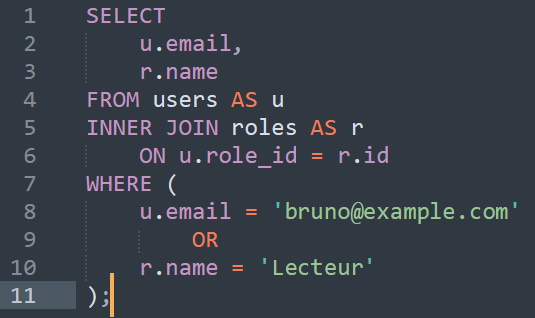
ou encore dans un éditeur SQL comme suit :
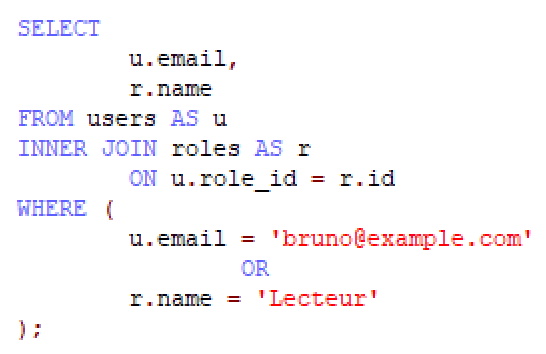
Si vous avez vraiment besoin de requêtes brutes et si vous voulez toujours la coloration syntaxique, vous pouvez mettre chaque requête dans son propre fichier query.sql. De cette façon, l'éditeur sait qu'il doit utiliser la coloration syntaxique SQL. Il faut ensuite appeler le contenu de ce fichier aux bons endroits.
/* ... */
// Requête SQL à considérer
connection.query(
fs.readFileSync('./raw-sql-fix-2.sql', { encoding: 'utf8' })
, function (err, rows) {
// Résultat
console.log(rows);
/*
`[
{ email: 'bruno@example.com', name: 'Éditeur' },
{ email: 'nyx@example.com', name: 'Lecteur' },
{ email: 'noctalie@example.com', name: 'Lecteur' },
{ email: 'dayski@example.com', name: 'Lecteur' }
]`
*/
/* ... */
});
Pour exécuter ce code, utiliser la commande node raw-sql-fix-3.js.
Pas très élégant sachant que même ainsi, les ? éventuels que vous utiliseriez dans le fichier original .sql seront interprétés comme des erreurs par un analyseur syntaxique et que vous serez alors incapable de gérer le découpage du code SQL dans différentes variables en fonction de vos besoins.
Problème 4 : coquilles dans les noms de tableaux ou de colonnes
Ce groupe d'erreurs est plus difficile à mettre en évidence par un analyseur syntaxique que le cas des erreurs de syntaxes SQL. Désormais, le code de vérification ne doit pas seulement savoir comment fonctionne le SQL, il doit aussi connaître vos données. Le schéma de la base de données pour être plus précis.
Le code suivant par exemple, avec une coquilles comme usrs dans un fichier raw-sql-issue-4.sql
SELECT * FROM usrs
va silencieusement retourner undefined comme dans le cas d'une coquille au niveau de la syntaxe :
/* ... */
// Requête SQL à considérer
connection.query(
fs.readFileSync('./raw-sql-issue-4.sql', { encoding: 'utf8' })
, function (err, rows) {
// Résultat
console.log(rows);
// `undefined`
/* ... */
});
Pour exécuter ce code, utiliser la commande node raw-sql-fix-4.js.
quand bien même avec un analyseur syntaxique .sql votre éditeur vous dirait que votre requête est parfaitement fonctionnelle. On en revient encore une fois au copier/coller dans un réel analyseur qui connaitrait la base de donnée.
Cependant, comme précédemment, ce problème peut être détecté à l'exécution avec une gestion des erreurs :
/* ... */
// Requête SQL à considérer
connection.query(
fs.readFileSync('./raw-sql-issue-4.sql', { encoding: 'utf8' })
, function (err, rows) {
if (err) throw err;
// Error: Table 'raw_builder_orm.usrs' doesn't exist
/* ... */
Pour exécuter ce code, utiliser la commande node raw-sql-fix-4.js.
Problème 5 : extension de requête
Si vous disposez d'une requête analytique, il est intéressant de pouvoir y apporter de légères modifications. Par exemple, imaginez des données de suivi pour lesquelles vous souhaitez savoir combien d'utilisateurs ont cliqué sur un bouton. Vous pourriez avoir une « requête de base » pour cela. En fonction du cas d'utilisation, vous pourriez vouloir filtrer en fonction d'une certaine période ou de certaines caractéristiques de l'utilisateur. Il est possible d'étendre une requête lorsque vous disposez de SQL brut, mais c'est fastidieux. Vous devez toucher à la requête d'origine et ajouter des espaces réservés.
/* ... */
let select;
let inner;
let where;
function runQuery(callback) {
// Requête SQL à considérer
connection.query(`
SELECT ${select.join(', ')}
FROM users AS u
${inner.join(' ')}
${where.length ? 'WHERE ' + where.join(' ') : ''};
`, function (err, rows) {
// Résultat
console.log(rows);
/*
`[
{ email: 'admin@example.com' },
{ email: 'bruno@example.com' },
{ email: 'dayski@example.com' },
{ email: 'magalie@example.com' },
{ email: 'noctalie@example.com' },
{ email: 'nyx@example.com' }
]`
*/
/*
`[
{ email: 'bruno@example.com', name: 'Éditeur' },
{ email: 'nyx@example.com', name: 'Lecteur' },
{ email: 'noctalie@example.com', name: 'Lecteur' },
{ email: 'dayski@example.com', name: 'Lecteur' }
]`
*/
connection.end();
});
callback && callback()
}
connection.connect(function (err, handshakeResult) {
select = [
`u.email`,
]
inner = []
where = []
runQuery(function () {
select = [
`u.email`,
`r.name`,
]
inner = [
`INNER JOIN roles AS r
ON u.role_id = r.id`,
]
where = [
`u.email = 'bruno@example.com' OR`,
`r.name = 'Lecteur'`
]
runQuery();
});
});
Pour exécuter ce code, utiliser la commande node raw-sql-fix-6.js.
Nous voyons également aisément ici comment il est illusoire dans ce cas d'espérer résoudre les problèmes précédemment mentionnés dans ce cas de figure (analyse syntaxique dans l'éditeur, colorisation, mise dans un fichier séparé, etc.).
Problème 6 : gestion du changement
Les bases de données changent au fil du temps. Avec le SQL brut, vous ne bénéficiez généralement d'aucun support pour cela. Vous devez migrer le schéma et toutes les requêtes vous-même : à savoir qu'il faut vous même vous arranger pour que la base de donnée soit mise à jour avec la bonne version du code qui tourne : que ce soit lors du chargement d'un code plus évolué ou d'un code moins évolué que ceux qu'il y a en base de donnée. Une telle gestion est appelée un système de migration de base de donnée. Nous développerons plus ce point quand nous le résoudrons plus loin dans cet article.
Constructeur de requêtes dit Query Builder
Les bibliothèques qui sont écrites dans le langage de programmation que vous utilisez et qui utilisent des classes et des fonctions natives pour construire des requêtes SQL sont appelées constructeurs de requêtes (“Query Builder”). Les requêtes sont construites par une interface orientée objet qui utilise le chaînage de méthodes dans le cas du JavaScript par exemple :
query = knex.from('users')
.select('*')
.where({
role_id: 1
})
Il existe également des outils graphiques qui sont parfois appelés constructeurs de requêtes, mais dans cet article, nous n'en parlerons pas.
Python a Pypika, PHP a Doctrine, Java a QueryDSL et JOOQ.
Knex est un exemple de générateur de requêtes en JavaScript. L'exemple de requête ci-dessus peut être construit et exécuté comme ceci :
const knex = require('knex')({
client: 'mysql2',
connection: {
host : 'localhost',
user : 'root',
password : 'root',
database : 'raw_builder_orm'
}
});
// Données provenant de la requête cliente
let query = knex.from('users');
/* ... */
// ...plus tard après plusieurs conditions...
query.select('id');
/* ... */
// ...et encore plus tard après plusieurs demandes de paramètres...
query.where({
email: 'bruno@example.com',
password: 'foo'
});
/* ... */
// ...et encore plus tard alors qu'on ne veut pas l'`id`, mais l'`email`...
query
.clear('select')
.select('email');
/* ... */
// ...et finalement, plus tard, alors que l'utilisateur est administrateur, je veux aussi voir l'`id` de role du membre.
query.select('role_id')
// Requête SQL générée
console.log(query.toSQL().toNative());
/*
`{
sql: 'select `email`, `role_id` from `users` where `email` = ? and `password` = ?',
bindings: [ 'bruno@example.com', 'foo' ]
}`
*/
// Exécution de la requête
query.then((rows) => {
// Résultat
console.log(rows);
// `[ { email: 'bruno@example.com', role_id: 2 } ]`
}).catch((err) => {
throw err;
})
.finally(() => {
knex.destroy();
});
Pour exécuter ce code, utiliser la commande node query-builder.js.
Notez que la requête résultante est toujours la même que dans le code brut. Elle a juste été construite d'une autre manière. Cela signifie que les performances de la base de données sont toujours les mêmes. Et comme la construction de la requête n'est pas une tâche complexe, les performances globales de l'application devraient rester les mêmes.
Vous pouvez constater que de cette manière, la requête est plus facile à étendre et à réutiliser que lorsqu'il fallait nous même gérer select, inner et where. Vous pouvez par exemple imaginer que vous avez un ensemble de jointures complexes et beaucoup d'instructions WHERE. Avec une requête SQL brut, vous commencerez à ajouter des bouts de chaine de caractère un peu partout. Avec un générateur de requêtes, il est plus simple d'étendre et de réutiliser les requêtes. Pour la rendre réutilisable, il faut exposer la requête query quelque part et la continuer par le chainage. Vous pouvez même changer d'avis et retirer quelque chose que vous aviez précédemment ajouté à la requête.
Le constructeur de requêtes empêche les coquilles dans les parties proposées .select, .from et .where de votre éditeur de code dans l'exemple ci-dessus. Il n'est cependant d'aucune utilité pour les noms de colonnes ou de tables, car il s'agit toujours de chaînes de caractères. En d'autres termes : un constructeur de requêtes résout les problèmes :
- 1 : injections SQL,
- 2 : coquilles dans les commandes SQL,
- 3 : absence de support pour l'éditeur et
- 5 : extension de requête
mais ne résous pas les problèmes suivants :
- 4 : coquilles dans les noms de tableaux ou de colonnes et
- 6 : gestion du changement.
Mappage d'objet-relationnel dit ORM
Les mappages d'objet-relationnel ou ORM (“Object-Relational Mapper”) créent une représentation en objet pour chaque table de base de données. De cette façon, il y a une représentation des tables dans le langage JavaScript qui permet à toutes les fonctionnalités d'un écosystème de développement JavaScript, telles que l'auto-complétions, la mise en évidence de la syntaxe et la connaissance de l'existence ou non d'un nom de table ou de colonne, de fonctionner. De ce fait, en plus de résoudre les 4 problèmes déjà résolu par les constructeurs de requête, un mappage d'objet-relationnel également le problème 4 évoqué dans la partie SQL brut.
Les mappages d'objet-relationnel sont extrêmement populaires dans de nombreux langages : Java a Hibernate, PHP a Eloquent, Ruby a activerecord, Python a SQLAlchemy.
JavaScript a Sequelize ou TypeORM pour le TypeScript.
Voici à quoi ressemble notre exemple de bibliothèque avec Sequelize :
const { Sequelize, DataTypes } = require('sequelize');
const sequelize = new Sequelize('raw_builder_orm', 'root', 'root', {
host: 'localhost',
dialect: 'mysql'
});
// Définition des modèles
const Roles = require('./models/roles.js')(sequelize, DataTypes);
const Users = require('./models/users.js')(sequelize, DataTypes);
// Association des modèles
const models = { Roles, Users };
Object.values(models)
.filter(model => typeof model.associate === 'function')
.forEach(model => model.associate(models));
(async function () {
await sequelize.sync({ alter: true });
const users = await Users.findAll({
where: {
email: 'bruno@example.com'
}
});
// Résultat
console.log(users);
/*
`[
Users {
dataValues: {
id: 2,
roleId: 2,
email: 'bruno@example.com',
password: 'foo',
role_id: 2
},
_previousDataValues: {
id: 2,
roleId: 2,
email: 'bruno@example.com',
password: 'foo',
role_id: 2
},
_changed: Set {},
_options: {
isNewRecord: false,
_schema: null,
_schemaDelimiter: '',
raw: true,
attributes: [Array]
},
isNewRecord: false
}
]`
*/
})();
Avec pour le modèle User :
const { Model } = require('sequelize');
module.exports = (sequelize, DataTypes) => {
class Users extends Model {
static associate({ Roles }) {
Users.belongsTo(Roles, {
foreignKey: {
name: 'role_id',
allowNull: false
}
});
}
};
Users.init({
id: {
type: DataTypes.INTEGER,
allowNull: false,
primaryKey: true,
autoIncrement: true
},
roleId: {
field: 'role_id',
type: DataTypes.INTEGER,
allowNull: false
},
email: {
type: DataTypes.STRING,
allowNull: false
},
password: {
type: DataTypes.STRING,
allowNull: false
}
}, {
sequelize,
tableName: 'users',
indexes: [{
name: 'email_idx',
fields: ['email']
}, {
name: 'password_idx',
fields: ['password']
}],
createdAt: false,
updatedAt: false
});
return Users;
};
et pour le modèle Role :
const { Model } = require('sequelize');
module.exports = (sequelize, DataTypes) => {
class Roles extends Model {
static associate({ Users }) {
Roles.hasMany(Users, {
foreignKey: {
name: 'role_id',
allowNull: false
}
});
}
};
Roles.init({
id: {
type: DataTypes.INTEGER,
allowNull: false,
primaryKey: true,
autoIncrement: true
},
name: {
type: DataTypes.STRING,
allowNull: false
}
}, {
sequelize,
tableName: 'roles',
indexes: [{
name: 'name_idx',
fields: ['name']
}],
createdAt: false,
updatedAt: false
});
return Roles;
};
Pour exécuter ce code, utiliser la commande node orm.js.
Un point intéressant des mappages d'objet-relationnel est qu'ils aident parfois à gérer les changements ce qui résout notre problème 6 évoqué dans la partie sur le SQL brut. En JavaScript, il y a Sequelize qui peut détecter automatiquement quand vos modèles ont changé par rapport au dernier état connu de la base de données. Sequelize peut alors gérer des fichiers de migration de schéma pour vous. Ils ressemblent à cela :
module.exports = {
up: async (queryInterface, Sequelize) => {
await queryInterface.addColumn('Users', 'birthDate', {
field: 'birth_date',
type: Sequelize.DataTypes.DATE,
allowNull: true
});
},
down: async (queryInterface, Sequelize) => {
await queryInterface.removeColumn('Users', 'birthDate');
}
};
Pour exécuter ce code, utiliser la commande npx sequelize-cli db:migrate pour ajouter la colonne birth_date et npx sequelize-cli db:migrate:undo pour retirer la colonne birth_date.
Avec un mappage d'objet-relationnel donc, il faut faire un effort initial pour représenter la base de données dans le code de sorte qu'il y ait des objets qui représentent les tables de la base de données. Après cet effort initial, vous devez vous assurer que la base de données est synchronisée avec la base du code de votre projet. Ce que vous obtenez de cet effort est un développement plus rapide lorsque vous avez juste besoin d'écrire de nouvelles requêtes simples de manipulation CRUD d'objet. Comme vous pouvez également bénéficier de la coloration syntaxique et du formatage automatique, cela peut également réduire la maintenance en rendant les requêtes plus faciles à lire.
Cependant, là ou les constructeurs de requêtes ne résolvaient pas tous les problèmes, il n'en apportait pas particulièrement de nouveau. Ici, nous avons effectivement résolue les 6 problèmes précédemment listés mais, si nous n'y prenons pas garde, créons de nouveaux problèmes… silencieux. Voyons cela à travers trois exemple qui traite plus où moins du même problème mais sous trois angles différents.
Problème A : sur-récupération
Lorsque vous lancez des requêtes avec des mappages d'objet-relationnel, vous avez tendance à obtenir plus que ce dont vous avez besoin. Par exemple, si vous vouliez utiliser le mappage d'objet-relationnel pour obtenir la liste des utilisateurs appartenant à un rôle, vous pourriez procéder comme suit :
/* ... */
(async function () {
const role = await Roles.findOne({
where: { name: 'Lecteur' }
})
const result = await Users.findAll({
where: { roleId: role.id },
});
// Résultat
console.log(JSON.stringify(role, null, 2));
/*
`{
"id": 3,
"name": "Lecteur"
}`
*/
result.forEach((item) => {
console.log(JSON.stringify(item, null, 2));
});
/*
`{
"id": 4,
"roleId": 3,
"email": "nyx@example.com",
"password": "baz",
"role_id": 3
}
{
"id": 5,
"roleId": 3,
"email": "noctalie@example.com",
"password": "fooz",
"role_id": 3
}
{
"id": 6,
"roleId": 3,
"email": "dayski@example.com",
"password": "far",
"role_id": 3
}`
*/
})();
Pour exécuter ce code, utiliser la commande node orm-issue-1.js.
Alors la base de données recevrait ces deux requêtes :
SELECT
`id`, `name`
FROM `roles` AS `Roles`
WHERE
`Roles`.`name` = 'Lecteur'
LIMIT 1;
# ~0.005 secondes d'exécution dans le pire des cas
SELECT
`id`,
`role_id` AS `roleId`,
`email`,
`password`,
`role_id`
FROM `users` AS `Users`
WHERE
`Users`.`role_id` = 3;
# ~0.006 secondes d'exécution dans le pire des cas
C'est inefficace pour de multiples raisons :
- Je n'avais pas besoin de récupérer d'informations sur le rôle.
- La base de données doit exécuter deux requêtes au lieu d'une.
- Je ne voulais pas l'id des utilisateurs ou d'autres informations.
Bien sûr, il s'agit d'un exemple minuscule où cela n'a pas d'importance. Mais imaginez que votre requête renvoie plusieurs centaines de lignes et comporte également plusieurs centaines de colonnes. Et peut-être que certaines d'entre elles seraient remplies d'un contenu assez important, par exemple un LONGBLOB.
Bien sûr, vous pourriez résoudre cela en regardant dans la documentation comment faire une jointure interne et limiter les colonnes récupérées :
/* ... */
(async function () {
const result = await Roles.findOne({
where: { name: 'Lecteur' },
attributes: [],
include: {
model: Users,
attributes: [Users.rawAttributes.email.field],
required: true
}
});
// Résultat
console.log(JSON.stringify(result, null, 2));
/*
`{
"Users": [
{
"email": "nyx@example.com"
},
{
"email": "noctalie@example.com"
},
{
"email": "dayski@example.com"
}
]
}`
*/
result.Users.forEach((item) => {
console.log(JSON.stringify(item, null, 2));
});
/*
`{
"email": "nyx@example.com"
}
{
"email": "noctalie@example.com"
}
{
"email": "dayski@example.com"
}`
*/
})();
Pour exécuter ce code, utiliser la commande node orm-issue-2.js.
ce qui donne lieu à cette requête :
SELECT
`Roles`.*,
`Users`.`id` AS `Users.id`,
`Users`.`email` AS `Users.email`
FROM (
SELECT `Roles`.`id`
FROM `roles` AS `Roles`
WHERE `Roles`.`name` = 'Lecteur' AND (
SELECT `role_id`
FROM `users` AS `Users`
WHERE (
`Users`.`role_id` = `Roles`.`id`)
LIMIT 1
) IS NOT NULL LIMIT 1
) AS `Roles`
INNER JOIN `users` AS `Users`
ON `Roles`.`id` = `Users`.`role_id`;
# ~0.11 secondes d'exécution dans le pire des cas
Si effectivement on limite le nombre de requête vers la base de données (ce qui n'est pas négligeable), maintenant le SQL généré et le temps d'exécution de la requête sont encore pire ! Cela montre parfaitement comment vous pouvez obtenir le bon résultat mais d'une manière très complexe en utilisant un mappage d'objet-relationnel. Le code produit est ici bien compliqué, et le temps d'exécution supérieur à ce que l'on pourrait faire.
Avec un simple changement, l'utilisation de findAll au lieu de findOne, voici alors ce que l'on obtient :
/* ... */
(async function () {
const [result] = await Roles.findAll({
where: { name: 'Lecteur' },
attributes: [],
include: {
model: Users,
attributes: [Users.rawAttributes.email.field],
required: true
}
});
// Résultat
console.log(JSON.stringify(result, null, 2));
/*
`{
"Users": [
{
"email": "nyx@example.com"
},
{
"email": "noctalie@example.com"
},
{
"email": "dayski@example.com"
}
]
}`
*/
result.Users.forEach((item) => {
console.log(JSON.stringify(item, null, 2));
});
/*
`{
"email": "nyx@example.com"
}
{
"email": "noctalie@example.com"
}
{
"email": "dayski@example.com"
}`
*/
})();
Pour exécuter ce code, utiliser la commande node orm-fix-2.js.
Ce qui donne cette requête :
SELECT
`Roles`.`id`,
`Users`.`id` AS `Users.id`,
`Users`.`email` AS `Users.email`
FROM `roles` AS `Roles`
INNER JOIN `users` AS `Users`
ON `Roles`.`id` = `Users`.`role_id`
WHERE
`Roles`.`name` = 'Lecteur';
# ~0.005 secondes d'exécution dans le pire des cas
Les mappages d'objet-relationnel permettent donc de créer facilement des requêtes qui sont problématiques de manière subtile comme le démontre les exemples précédents. Imaginez que vous ayez reçu l'exemple orm-issue-1.js ou orm-issue-2.js pour l'examiner. Ils font ce qu'il faut, les tests unitaires ne sont pas non plus terriblement lents. Seriez-vous certain de repérer le double appel à la base de donnée ou la complexité générée inutile ? Et lorsque la requête souhaitée devient beaucoup plus complexe ?
Pour le SQL brut et les constructeurs de requêtes, vous devez faire des efforts pour maîtriser des requêtes complexes similaires mais il est difficile d'écrire une requête trop alambiquée sans s'en rendre compte.
Problème B : nombre de requête N+1
Imaginons que vous vouliez afficher une liste de tous les utilisateurs avec les noms de leur rôle. En SQL brut, vous exécuteriez cette requête :
SELECT
u.email,
r.name
FROM users AS u
INNER JOIN roles AS r
ON u.role_id = r.id
Avec un mappage d'objet-relationnel, vous pourriez être tenté de faire cela :
/* ... */
(async function () {
const result = await Users.findAll();
console.log(JSON.stringify(result, null, 2));
/*
`[
{
"id": 1,
"roleId": 1,
"email": "admin@example.com",
"password": "unknown",
"role_id": 1
},
{
"id": 2,
"roleId": 2,
"email": "bruno@example.com",
"password": "foo",
"role_id": 2
},
{
"id": 3,
"roleId": 2,
"email": "magalie@example.com",
"password": "bar",
"role_id": 2
},
{
"id": 4,
"roleId": 3,
"email": "nyx@example.com",
"password": "baz",
"role_id": 3
},
{
"id": 5,
"roleId": 3,
"email": "noctalie@example.com",
"password": "fooz",
"role_id": 3
},
{
"id": 6,
"roleId": 3,
"email": "dayski@example.com",
"password": "far",
"role_id": 3
}
]`
/* ... */
// ...plus tard alors que vous avez besoin d'afficher les noms de role...
result.forEach(async (user) => {
const { Role } = await Users.findOne({
where: { id: user.id },
include: {
model: Roles,
required: true
}
});
console.log(JSON.stringify(Role.name, null, 2));
});
/*
`"Administrateur"`
`"Éditeur"`
`"Éditeur"`
`"Lecteur"`
`"Lecteur"`
`"Lecteur"`
*/
})();
Pour exécuter ce code, utiliser la commande node orm-issue-3.js.
Cela semble correct parce qu'on sélectionne bien les éléments en dehors de la fonction forEach, mais pour chaque élément, une requête est lancée car findOne est bien dans la boucle. Ainsi, si vous avez reçu n utilisateur(s) dans la première requête, vous allez exécuter n requête(s) supplémentaires dont vous n'êtes potentiellement pas conscient. Vous avez n + 1 requêtes au lieu de 1. Avec Sequelize, comme seules les fonctions find* font des SELECT en base, il reste relativement aisé de faire attention, mais il existe pléthore de fonctions dans différents mappages d'objet-relationnel qui peuvent réellement vous induire en erreur.
Dans notre exemple précédent, puisque nous avons 6 utilisateurs, nous avions donc 7 requêtes qui pourraient n'en être que 2 avec le code suivant :
/* ... */
(async function () {
const result = await Users.findAll();
console.log(JSON.stringify(result, null, 2));
/*
`[
{
"id": 1,
"roleId": 1,
"email": "admin@example.com",
"password": "unknown",
"role_id": 1
},
{
"id": 2,
"roleId": 2,
"email": "bruno@example.com",
"password": "foo",
"role_id": 2
},
{
"id": 3,
"roleId": 2,
"email": "magalie@example.com",
"password": "bar",
"role_id": 2
},
{
"id": 4,
"roleId": 3,
"email": "nyx@example.com",
"password": "baz",
"role_id": 3
},
{
"id": 5,
"roleId": 3,
"email": "noctalie@example.com",
"password": "fooz",
"role_id": 3
},
{
"id": 6,
"roleId": 3,
"email": "dayski@example.com",
"password": "far",
"role_id": 3
}
]`
/* ... */
// ...plus tard alors que vous avez besoin d'afficher les noms de rôle...
const users = await Users.findAll({
where: {
id: result.map(d => d.id)
},
include: {
model: Roles,
required: true
}
});
users.forEach(async ({ Role }) => {
console.log(JSON.stringify(Role.name, null, 2));
});
/*
`"Administrateur"`
`"Éditeur"`
`"Éditeur"`
`"Lecteur"`
`"Lecteur"`
`"Lecteur"`
*/
})();
Pour exécuter ce code, utiliser la commande node orm-fix-3.js.
Problème C : abstractions qui fuient
L'abstraction est une lame à double tranchant : d'une part, elle simplifie les choses. Le développeur n'a pas à s'occuper des détails de l'interaction avec la base de données et de la construction des requêtes ; il pourrait même ne rien connaitre du SQL. D'autre part, les développeurs ne savent pas ce qu'ils interrogent réellement dans la base de données ni combien de requêtes ils envoient. Pour cette raison, certaines interactions sont plus inefficaces (genre beaucoup plus inefficaces !) qu'elles ne devraient l'être en terme de performance (exemple).
Par exemple, imaginez que vous fournissiez la liste des id de rôle qui vous intéressent et qu'on vous renvoie la liste de tous les utilisateurs possédant ces rôles. Vous pourriez être tenté de faire quelque chose comme ceci :
/* ... */
(async function () {
const roleIds = [2, 3];
const usersIds = {};
await Promise.all(roleIds.map(async (roleId) => {
usersIds[roleId] = await Users.findAll({
where: { roleId: roleId }
});
usersIds[roleId] = usersIds[roleId].map(x => x.id)
}));
console.log(JSON.stringify(usersIds, null, 2));
/*
`{
"2": [
2,
3
],
"3": [
4,
5,
6
]
}`
*/
})();
Pour exécuter ce code, utiliser la commande node orm-issue-4.js.
Maintenant, vous envoyez une requête une fois pour chaque rôle. Bien sûr, vous pouvez faire cela en une seule requête avec les mêmes pièces de code ; et c'est là que c'est trompeur. Deux écritures très similaires produisent des résultats de performance bien différent. Ici, même si la boucle ci-dessus ne semble pas si mauvaise, vous avez une connexion réseau entre les deux. Voici comment faire avec une seule requête :
/* ... */
(async function () {
const roleIds = [2, 3];
const usersIds = {}
const users = await Users.findAll({
where: { roleId: roleIds }
});
users.forEach((user) => {
usersIds[user.roleId] = usersIds[user.roleId] ? [...usersIds[user.roleId], user.id] : [user.id]
})
console.log(JSON.stringify(usersIds, null, 2));
/*
`{
"2": [
2,
3
],
"3": [
4,
5,
6
]
}`
*/
})();
Pour exécuter ce code, utiliser la commande node orm-fix-4.js.
Cela met en évidence le problème d'abstraction qui fui auquel un mappage d'objet-relationnel peut conduire : la manière d'utiliser quelque chose qui se voulait être abstrait change tout de même les performances sous-jacentes et l'on ne peut pas se contenter de ne pas connaître le résultat produit par le mappage d'objet-relationnel quand la performance est un élément important du développement.
Types de requêtes et changements progressifs
Nous avons utilisé des exemples de requête très simple. Bien sûr, les requêtes peuvent devenir beaucoup plus compliquées. J'ai moi-même écrit des requêtes de plusieurs centaines de lignes.
Pour savoir laquelle des trois approche est la plus pertinente pour un cas de figure précis, on distingue généralement deux groupes de charges de travail : le traitement transactionnel en ligne (“Online transaction processing” ou OLTP) ou le traitement analytique en ligne (“Online analytical processing” ou OLAP).
- Les charges de travail OLTP ont une grande quantité de petites insertions / mises à jour / suppressions, tandis que
- les charges de travail OLAP exécutent une petite quantité de requêtes sélectionnées complexes pour l'analyse.
Bien sûr, si vous êtes dans un scénario où la plupart de vos requêtes sont plutôt simples, il est facile de passer à un constructeur de requêtes ou à un mappage d'objet-relationnel. Mais si vous avez des requêtes complexes, le passage à un mappage d'objet-relationnel peut même être impossible.
C'est là que les changements progressifs entrent en jeu. Certains mappage d'objet-relationnel / constructeurs de requêtes vous permettent d'utiliser du SQL brut. Et certains constructeurs de requêtes vous permettent d'abord d'utiliser des chaînes de caractères pour les noms de tables et de colonnes, puis de passer aux objets à votre guise.
Si vous pouvez vous contenter du degré d'abstraction qui vous semble naturel, votre vitesse de développement n'est pas entravée. Si vous avez une requête complexe que vous voulez d'abord bien faire, écrivez-la simplement de manière brute. Il est toujours possible de la transformer ultérieurement en expression à l'aide d'un générateur de requêtes.
Il est donc recommandé pour un travail OLTP de travailler avec une approche de mappage objet-relationnel qui pourra même aisément supporter des requêtes analytique simple. Cependant, il est plutôt recommandé pour un travail OLAP de jouer avec un constructeur de requêtes qui pourra étendre vos besoins. Dans les cas les plus rares ou la complexité analytique est trop grande pour être même assuré par un constructeur de requête, vous pouvez alors passer par du SQL brut en faisant très attention aux problèmes mentionnés en parties 1.
En JavaScript, si vous utilisez le mappage d'objet-relationnel Sequelize, vous pouvez toujours récupérer vos données de manière brute ou même directement instancier des modèles depuis des du SQL brut. De même, si vous utilisez le constructeur de requêtes Knex, vous pouvez également directement utiliser du SQL Brut.
Conclusion
Le SQL brut est assurément le moyen le plus puissant d'interagir avec votre base de données, car il s'agit du langage natif des bases de données. L'inconvénient est que vous risquez d'utiliser des fonctionnalités spécifiques à cette base de données, ce qui rendra plus difficile un futur changement de base de données. Un autre inconvénient est l'absence des fonctions essentielles de l'éditeur, comme la coloration syntaxique et l'auto-complétion. L'extension des requêtes est fastidieuse et le risque d'injections SQL est plus élevé.
À l'autre extrême, les mappages d'objet-relationnel fournissent la plus haute forme d'abstraction et empêchent les fautes de frappe non seulement dans les mots-clés SQL, mais aussi dans les noms de tables et de colonnes. Ils sont plus couteux à mettre en place que les constructeurs de requêtes, tant du point de vue de la courbe d'apprentissage que de celui des frais de développement initiaux. Comme ils font beaucoup d'abstraction, le risque d'exécuter des requêtes coûteuses ou trop nombreuses est plus élevé. Cependant, une fois en place et pour toutes les actions communes et redondantes, il ferra gagner énormément de temps et de maintenance.
Et à mi-chemin entre les deux, les constructeurs de requêtes n'ajoutent que peu de frais de développement et aucun frais d'exécution par rapport au SQL brut et empêchent les fautes de frappe dans les mots-clés SQL. Ils facilitent l'extension des requêtes et rendent les injections SQL plus difficiles. Ils sont alors un bon compromis entre les défauts des deux autres approches.
À propos
Cet article est adapté de l'excellent article de Martin Thoma qui a servi de guide à la rédaction et à la confection des exemples de cette version française en JavaScript (initialement en Python et en anglais).